|
Index
Result
of benchmarking
Other benchmarking
Used
benchmark method
Table
of benchmarking results
Result
of benchmarking
After testing
different PCs, we found same results as we already see in our applications,
powered by smartGC. If there is no workload (as in beginnig
steps of benchmark, see below) there is no much difference
too.
But after
some point smartGC is still linear in its results and
standart GC is not. On a testing runs at a fast
PCs the difference is not so much (about 200-500%), but significant. On
slower PCs gap much bigger, up to 800% on yesterdays
PCs and amazing and unbelievable 11600% on old PCs.
Other
benchmarking
|
We
also testing some other areas of Xbase++ programs. Usually, smartGC
always 10-20% faster than native GC. For example, navigation with
XbpBrowse is up to 25% faster, and XML-parsing is up to 70% faster!
Testing with XbZLib also show perfomance increasing up to 50%.
Also,
some speed-up may be noticed in areas with massive functions calls,
especially with a lot of parameters and locals.
NEW:
Since version 1.3 there is new test programm written by Jack Duijf.
After installation see at \samples\jack duijf test\. This
test show amazing results: smartGC faster then standart GC from
40 to 150 times.
|
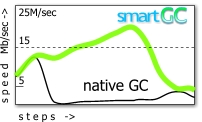 smartGC speed relative to native GC
smartGC speed relative to native GC
(based on testing 433Mz/64M/WinME) )
|
Used
benchmark method
For benchmarking
we use very simple program. Its creates an empty array and add to it an
test string while len of array below maxLen variable.
Then we resize array down by one element while array in not empty. This
is one step. Then we grow up test string by strPad
chars and repeat step again until 10 steps.
When program
reach tens step, total alloced memory is about 90% of installed RAM. Behaviour
of application near swapping edge is very important. Thats why we use
90% of RAM.
Also, this
benchmark was runned in two modes:
mode1: maxLen is 100,000
mode2:
maxLen is 10,000
On all PCs
was unloaded all programms and services and total amount of free physical
memory was about 70-80%.
| test
code listing: |
|
If mode1
maxLen:=100000
Else
maxLen:=10000
End
strPad:=Int( ((Memory(4)*1024*.9)/maxLen)/10
)
a:={}
addF:=.T.
pad:=strPad
While .T.
If addF
AAdd(a,Replicate("A",pad))
If Len(a)==maxLen
addF:=!addF
End
Else
ASize(a,Len(a)-1)
If Len(a)==0
//end of step
addF:=!addF
pad+=strPad
End
End
End
|
Why this
code good for benchmarking? There is some reasons:
- we emulate
using arrays and string (most used elements in xbase++ applications)
- array
size grows and reduces step by step
- amount
of alloced memory is near of swapping
Table
of benchmarking results
To view real
world results we tested 3 types of PCs:
•
Modern PC:
2.5GHz/512M/WinXP
| mode
1 Large array/Small pad |
| step |
standart
GC |
|
smartGC |
| run
1 |
run
2 |
run
3 |
run
1 |
run
2 |
run
3 |
| time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10. |
3.6s
1.7s
1.4s
1.6s
2.1s
14.9s
2.8s
4.0s
13.9s
4.9s
|
12.7M/s
52.8M/s
96.8M/s
117.4M/s
107.5M/s
18.6M/s
114.0M/s
92.5M/s
29.9M/s
94.6M/s
|
3.5s
2.2s
1.6s
2.2s
2.2s
56.6s
4.7s
3.1s
6.1s
36.7s
|
13.0M/s
41.6M/s
88.1M/s
82.6M/s
103.1M/s
4.9M/s
68.6M/s
119.8M/s
67.5M/s
12.6M/s
|
3.4s
2.5s
1.5s
3.5s
2.3s
70.2s
3.2s
4.0s
3.6s
41.1s
|
13.6M/s
36.4M/s
93.8M/s
52.5M/s
99.6M/s
3.9M/s
102.1M/s
92.1M/s
114.3M/s
11.2M/s
|
|
2.0s
1.6s
1.6s
1.8s
1.8s
2.0s
2.0s
2.1s
2.2s
9.4s
|
23.2M/s
58.1M/s
87.0M/s
104.0M/s
128.4M/s
139.8M/s
158.9M/s
172.0M/s
186.2M/s
49.2M/s |
2.1s
1.5s
1.5s
1.7s
1.8s
2.0s
2.1s
2.1s
2.2s
7.5s |
22.4M/s
59.9M/s
89.2M/s
110.8M/s
128.3M/s
141.2M/s
157.2M/s
171.9M/s
188.7M/s
61.2M/s |
1.9s
1.5s
1.6s
1.6s
1.8s
1.9s
2.0s
2.1s
2.2s
7.2s |
24.2M/s
60.5M/s
87.8M/s
112.6M/s
128.0M/s
146.2M/s
163.3M/s
174.1M/s
191.9M/s
63.9M/s |
| all |
50.9s |
|
118.9s |
|
135.2s |
|
|
26.4s |
|
24.4s |
|
23.7s |
|
|
•
Comments:
Overal
speed differences 200%-500%. Results show very smooth workload with
smartGC enabled. Standart GC sometimes went into processor
time eating stage (see step 6 for all runs with standart GC
in table above). In this situations smartGC faster
than native GC up to 35 times!
| mode
2 Small array/Large pad |
| step |
standart
GC |
|
smartGC |
| run
1 |
run
2 |
run
3 |
run
1 |
run
2 |
run
3 |
| time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10. |
2.2s
0.6s
0.6s
4.5s
12.4s
35.5s
30.9s
27.4s
24.6s
22.3s |
20.7M/s
153.8M/s
222.9M/s
41.0M/s
18.5M/s
7.8M/s
10.4M/s
13.4M/s
16.8M/s
20.6M/s |
1.7s
0.6s
0.6s
0.9s
12.5s
35.3s
30.3s
26.9s
24.1s
21.9s |
26.4M/s
155.1M/s
221.1M/s
210.4M/s
18.4M/s
7.8M/s
10.6M/s
13.7M/s
17.2M/s
21.0M/s |
1.6s
0.6s
0.6s
0.7s
14.3s
35.5s
30.6s
26.9s
24.0s
21.9s |
28.4M/s
151.6M/s
220.1M/s
271.4M/s
16.1M/s
7.8M/s
10.5M/s
13.7M/s
17.3M/s
21.0M/s |
|
0.9s
0.6s
0.6s
0.6s
2.1s
5.5s
5.1s
5.2s
5.2s
7.1s |
49.5M/s
155.1M/s
232.3M/s
285.3M/s
109.7M/s
50.7M/s
63.8M/s
70.6M/s
79.6M/s
64.8M/s |
0.9s
0.6s
0.6s
0.6s
2.0s
5.1s
5.4s
5.3s
4.7s
6.2s |
50.6M/s
156.2M/s
222.6M/s
287.1M/s
117.2M/s
54.5M/s
59.6M/s
70.0M/s
88.1M/s
73.9M/s |
0.9s
0.6s
0.6s
0.7s
2.2s
5.4s
5.2s
5.1s
4.8s
27.6s |
51.7M/s
154.6M/s
235.5M/s
271.8M/s
103.7M/s
51.4M/s
62.3M/s
72.5M/s
86.9M/s
16.7M/s |
| all |
161.1s |
|
154.9s |
|
156.7s |
|
|
32.9s |
|
31.4s |
|
53.0s |
|
|
•
Comments:
Overal
speed differences 300%-500%.
SmartGC is much faster and smoother too.
•
Yesterdays PC:
800MHz/128M/Win2000
| mode
1 Large array/Small pad |
| step |
standart
GC |
|
smartGC |
| run
1 |
run
2 |
run
3 |
run
1 |
run
2 |
run
3 |
| time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10. |
2.9s
3.1s
3.6s
3.6s
4.4s
3.6s
4.5s
21.4s
65.8s
26.8s |
3.9M/s
7.3M/s
9.4M/s
12.6M/s
13.0M/s
19.0M/s
17.8M/s
4.2M/s
1.6M/s
4.2M/s |
3.0s
3.1s
3.4s
12.9s
3.8s
10.8s
3.8s
12.3s
64.1s
25.3s |
3.8M/s
7.3M/s
9.9M/s
3.5M/s
15.1M/s
6.3M/s
21.1M/s
7.4M/s
1.6M/s
4.5M/s |
2.9s
3.0s
3.3s
3.6s
3.7s
3.7s
3.8s
10.0s
62.8s
31.1s |
3.9M/s
7.6M/s
10.4M/s
12.7M/s
15.5M/s
18.3M/s
20.7M/s
9.1M/s
1.6M/s
3.7M/s |
|
3.3s
3.1s
3.8s
3.2s
3.3s
3.4s
3.4s
7.7s
12.9s
26.4s |
3.5M/s
7.3M/s
9.0M/s
14.1M/s
17.0M/s
20.0M/s
23.2M/s
11.9M/s
7.9M/s
4.3M/s |
3.2s
2.9s
3.6s
3.1s
3.1s
3.2s
3.4s
10.6s
15.6s
31.5s |
3.6M/s
7.7M/s
9.5M/s
14.7M/s
18.1M/s
21.1M/s
23.5M/s
8.6M/s
6.5M/s
3.6M/s |
3.2s
3.1s
3.4s
3.3s
3.3s
3.4s
3.4s
5.4s
15.3s
29.7s |
3.5M/s
7.3M/s
9.9M/s
14.0M/s
17.0M/s
20.0M/s
23.2M/s
16.9M/s
6.7M/s
3.8M/s |
| all |
139.6s |
|
142.5s |
|
127.9s |
|
|
70.4s |
|
80.3s |
|
73.6s |
|
|
•
Comments:
Speed differences
about 200%. SmartGC is much faster and smoother than
native GC.
| mode
2 Small array/Large pad |
| step |
standart
GC |
|
smartGC |
| run
1 |
run
2 |
run
3 |
run
1 |
run
2 |
run
3 |
| time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10. |
0.6s
0.5s
1.1s
26.8s
26.7s
26.2s
30.9s
28.7s
26.1s
34.9s |
20.0M/s
44.7M/s
31.9M/s
1.7M/s
2.1M/s
2.6M/s
2.6M/s
3.2M/s
3.9M/s
3.3M/s |
0.5s
0.5s
0.6s
28.9s
29.2s
28.4s
30.6s
27.4s
24.4s
16.0s |
21.1M/s
42.2M/s
56.0M/s
1.6M/s
2.0M/s
2.4M/s
2.6M/s
3.3M/s
4.2M/s
7.1M/s |
0.6s
0.5s
0.6s
28.0s
28.8s
29.0s
30.6s
27.3s
24.4s
31.3s |
20.4M/s
42.3M/s
55.2M/s
1.6M/s
2.0M/s
2.4M/s
2.6M/s
3.3M/s
4.2M/s
3.7M/s |
|
0.6s
0.5s
0.6s
1.7s
1.8s
1.8s
2.0s
2.1s
4.0s
11.1s |
20.7M/s
43.2M/s
58.1M/s
26.7M/s
31.0M/s
37.1M/s
40.8M/s
43.0M/s
25.6M/s
10.3M/s |
0.6s
0.5s
0.6s
1.7s
1.8s
1.9s
1.9s
2.2s
3.4s
11.8s |
20.7M/s
44.0M/s
55.3M/s
26.2M/s
32.0M/s
36.5M/s
42.3M/s
41.7M/s
30.6M/s
9.7M/s |
0.6s
0.5s
0.6s
1.8s
1.8s
1.9s
2.0s
2.3s
5.1s
11.1s |
20.7M/s
43.8M/s
55.9M/s
25.5M/s
32.1M/s
36.8M/s
40.7M/s
40.0M/s
20.3M/s
10.2M/s |
| all |
202.4s |
|
186.6s |
|
201.1s |
|
|
26.3s |
|
26.3s |
|
27.6s |
|
|
•
Comments:
Speed differences
600%-800%! Native GC went into internal loop of garbaging at step
4 and smartGC easy won the battle.
•
Old PC: 433Hz/64M/WinME
| mode
1 Large array/Small pad |
| step |
standart
GC |
|
smartGC |
| run
1 |
run
2 |
run
3 |
run
1 |
run
2 |
run
3 |
| time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10. |
6.3s
6.3s
6.4s
2582.9s
3003.6s
1665.3s
4886.9s
27.7s
227.2s
35.7s |
0.9M/s
1.8M/s
2.6M/s
0.0M/s
0.0M/s
0.0M/s
0.0M/s
1.6M/s
0.2M/s
1.6M/s |
6.3s
6.1s
6.6s
6.2s
415.8s
2480.0s
172.9s
21.4s
25.0s
93.4s |
0.9M/s
1.9M/s
2.5M/s
3.6M/s
0.1M/s
0.0M/s
0.2M/s
2.1M/s
2.0M/s
0.6M/s |
6.6s
6.0s
6.4s
2571.2s
2993.3s
2208.0s
41.6s
28.4s
112.4s
34.2s |
0.9M/s
1.9M/s
2.6M/s
0.0M/s
0.0M/s
0.0M/s
0.9M/s
1.6M/s
0.5M/s
1.6M/s |
|
6.2s
6.7s
6.3s
6.3s
6.7s
7.9s
9.5s
15.8s
31.5s
25.4s |
0.9M/s
1.7M/s
2.7M/s
3.5M/s
4.2M/s
4.3M/s
4.1M/s
2.8M/s
1.6M/s
2.2M/s |
6.0s
6.2s
6.1s
6.2s
6.2s
6.9s
11.5s
24.6s
21.0s
34.2s |
0.9M/s
1.8M/s
2.8M/s
3.6M/s
4.6M/s
4.9M/s
3.4M/s
1.8M/s
2.4M/s
1.6M/s |
6.1s
6.5s
6.0s
6.2s
6.2s
8.3s
11.6s
23.5s
16.7s
16.5s |
0.9M/s
1.7M/s
2.8M/s
3.6M/s
4.5M/s
4.1M/s
3.4M/s
1.9M/s
3.0M/s
3.4M/s |
| all |
12440.2s |
|
3231.7s |
|
8001.8s |
|
|
122.1s |
|
128.5s |
|
107.3s |
|
|
•
Comments:
This results
really amazing us. Not a joke, speed differences about 2500-11600%.
SmartGC is unbelieviable faster than standart GC. On some steps
smartGC faster then native GC more than 400 times!
| mode
2 Small array/Large pad |
| step |
standart
GC |
|
smartGC |
| run
1 |
run
2 |
run
3 |
run
1 |
run
2 |
run
3 |
| time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
time |
speed |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10. |
0.8s
0.9s
68.8s
28.7s
58.4s
50.4s
46.3s
44.5s
49.2s
17.5s |
6.8M/s
12.4M/s
0.2M/s
0.8M/s
0.5M/s
0.7M/s
0.9M/s
1.0M/s
1.0M/s
3.2M/s |
0.8s
1.0s
80.7s
70.8s
57.8s
50.2s
49.1s
43.4s
17.4s
38.0s |
6.8M/s
11.5M/s
0.2M/s
0.3M/s
0.5M/s
0.7M/s
0.8M/s
1.0M/s
2.9M/s
1.5M/s |
0.8s
0.9s
47.2s
71.9s
58.7s
50.8s
47.8s
47.8s
15.9s
35.0s |
6.7M/s
12.7M/s
0.4M/s
0.3M/s
0.5M/s
0.7M/s
0.8M/s
0.9M/s
3.2M/s
1.6M/s |
|
0.8s
1.0s
1.5s
1.6s
1.9s
1.9s
2.1s
4.4s
12.7s
17.1s |
6.9M/s
11.9M/s
11.4M/s
13.9M/s
15.3M/s
17.6M/s
18.8M/s
10.4M/s
4.0M/s
3.3M/s |
0.9s
0.8s
1.5s
1.6s
1.7s
1.9s
2.1s
5.7s
16.2s
16.2s |
6.6M/s
13.6M/s
11.4M/s
14.1M/s
16.2M/s
18.1M/s
19.0M/s
7.9M/s
3.1M/s
3.5M/s |
0.9s
0.8s
1.5s
1.6s
1.8s
1.9s
2.1s
3.9s
17.4s
18.0s |
6.6M/s
13.8M/s
11.2M/s
13.8M/s
15.9M/s
18.0M/s
18.8M/s
11.7M/s
2.9M/s
3.1M/s |
| all |
364.8s |
|
408.7s |
|
376.6s |
|
|
44.8s |
|
48.5s |
|
49.6s |
|
|
•
Comments:
Speed differences
700%-900%! Native GC went into internal loop of garbaging at step
3. SmartGC on some steps was about 40 times faster,
and just at steps 9 and 10 was small slowdown because
of swapping.
©2006
Eleus Software |

